Did you know it would take 1.2 million mosquitoes, each sucking once, to completely drain the blood in an average human? The text analytics market value will be US$ 18.25 Bn by 2025. Interesting, isn’t it?
People are fascinated by numbers. Even if they aren’t necessarily true 😊. I believe there are many theories why it is so – about the evolution, genes, collective behavior… I like numbers, too. It’s comfortable to know exactly how many breads I should buy, to see numbers when comparing two possible scenarios before making the decision where to go for a vacation, to watch the reach of my posts on social media.
“If you can’t measure it, you can’t improve it.”
Data is something I can use to improve my business, my decisions, my lifestyle…
All in all, data is here to be measured.
Measures are numbers.
Data is numbers.
Wrong.
…but somehow many people think like this. Even though 80% of all data we generate is unstructured (not sure if the number is correct, but it looks better than “much”), we are still focused on analyzing and measuring numbers. And there is nothing wrong with it. However, there’s a whole new universe of data waiting for us to uncover the value in it. Unstructured data.







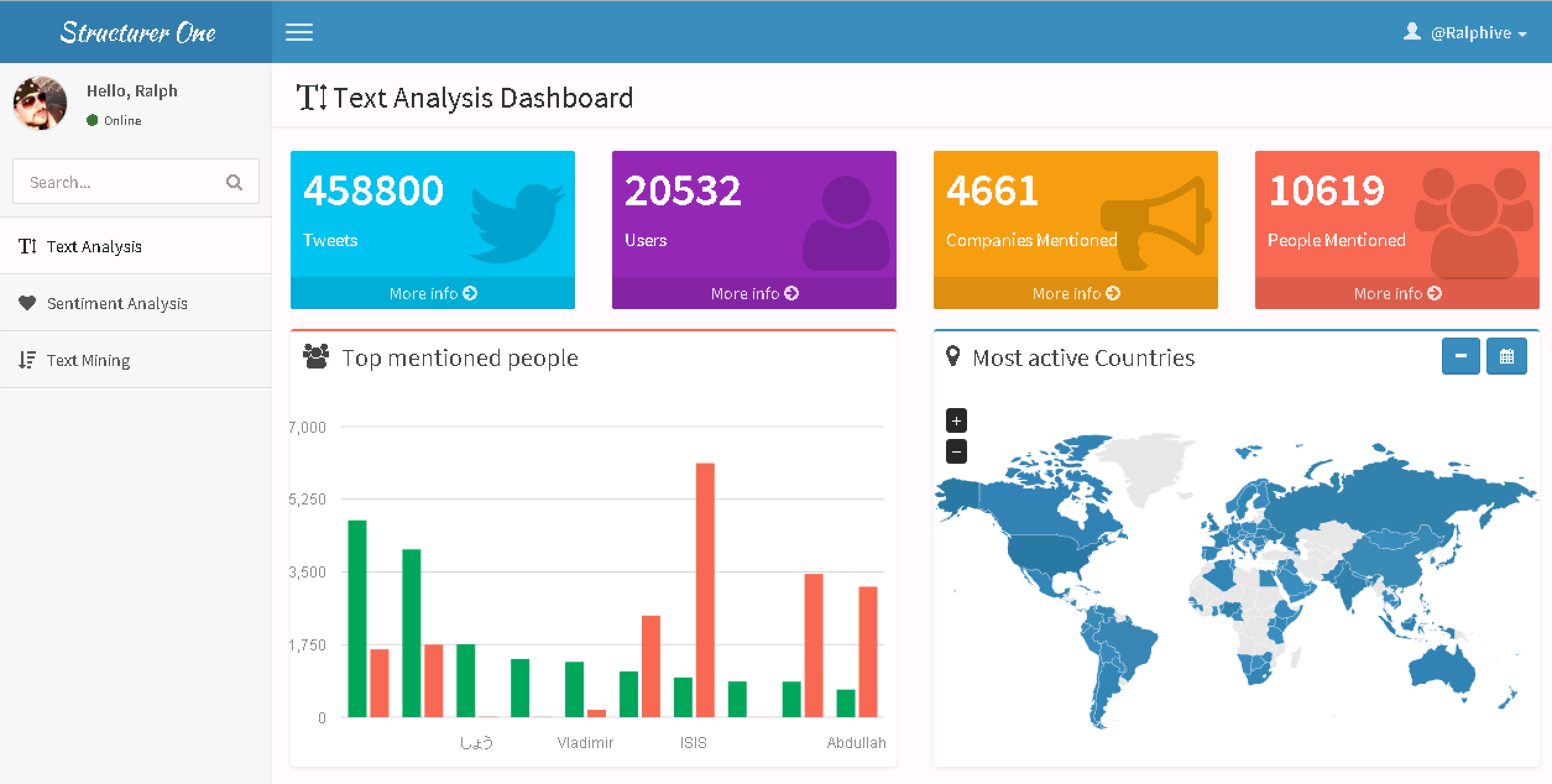
IS UNSTRUCTURED DATA ANALYTICS REAL?
For many people, unstructured data analytics is about face recognition, sentiment analysis of customers and followers, conversational analytics, or something else that sounds too far away from their daily schedule that they don’t even believe it can be a reality. They just read about it on the way to work and once they arrive, they open the e-mail and spreadsheets. What they don’t realize often is that every single e-mail they send to their colleagues or any note they enter in the spreadsheet is unstructured data.
Let me compare unstructured data to numbers and mathematics – your forecasts can be calculated by using tons of historical data, manual inputs, and neural networks above it. However, it’s not the only option. You can assume the data for next year will be the same as this one. Or you can calculate a moving average as a forecast, or use regression, time series analysis, and many more approaches. It’s not binary – you either use AI or nothing. It’s more like 50 shades of gray.
Unstructured data analytics isn't binary - you either use AI or nothing. It's more like 50 shades of gray.
With unstructured data, it’s the same. All these cool stuff like sentiment or conversational analytics are interesting but you don’t need to start with it when utilizing your unstructured data. So, what can you start with?
- Look for the word “password:” in your developers’ text files 😊
- Analyze the content of “note” type fields in databases and spreadsheets – search for specific customers, employees, account numbers…
- Search through many scripts in text files for a specific variable, field, or word
- Find all spreadsheets where a specific customer is mentioned, even if it’s in notes
- Isn’t there already documentation you’re working on?
- Isn’t there any personal or sensitive data in an e-mail sent outside your company?
- How many e-mails are sent inside your organization? How many words do they contain? Wouldn’t it be more efficient to organize a meeting about a specific topic (long e-mails) or implement a tool for internal chats (if many short e-mails are sent)?

THE PROCESS OF ANALYZING UNSTRUCTURED DATA
Interested? The next question is how to do it 😊. Naturally, in Qlik you have more options and it’s only up to you which one is the best fit for you and your use case. In general, there are 4 different steps of the process (in the end, unstructured data is still data):
STEP 1: LOAD THE DATA INTO QLIK
If you want to analyze the data, you need to have it collected somewhere. Qlik data model can be a good place.
- If the text is in a table column or on a webpage you can use Qlik native connectors
- For text files or scans you may find Mole Unstructured Data Connector useful
- You can also do this part outside of Qlik Sense and load results in your app
STEP 2: PREPARE THE DATA IN A QLIK SCRIPT
Parse data, normalize words, skip the punctuation, ignore short words if they aren’t relevant. All this can be done before analysis itself to have the most accurate results in the shortest time.
- Sometimes the simplest solution is the right one – Qlik native functions in the script
- For more advanced operations you can implement the SSE (Server Side Extension) called from the script
- You can also do this part outside of Qlik Sense and load results in your app
STEP 3: ANALYZE THE DATA IN A QLIK SCRIPT/SSE
And now there is the 3rd step. Analyze the data.
- Simple analytics can be done directly in Qlik Sense. Don’t you believe it? Wait for my next blog!
- For web data, you can try Web Connector
- SSE is a cool way how to do it, too, and a good one for advanced analytics 😊 – check this cool example by Nabeel Asif about covid-19 literature or presidential speeches analysis by Terezia Blaskova
- You can also do this part outside of Qlik Sense and load results in your app
STEP 4: VISUALIZE RESULTS
Because of the volume of unstructured data, it’s more than critical to know what the user needs to use the results for. Visualizing all words from files, billions of points in scatterplots isn’t necessarily a good idea.
- Naturally, you can also do this part outside of Qlik Sense … but why would you do that? 😋
…and one best practice in the end. Never ever forget to have fun when analyzing data. How about to find the most often used phrase by Arthur Conan Doyle or Jane Austen?
In my future blogs, I’ll elaborate more on specific topics regarding the unstructured data, especially by using Qlik native features since I think it’s a bit underestimated. And as you probably noticed, underestimated functions and features are exactly what I like to post about 😁.