
There was a long-held belief in my circles that Qlik calculation performance is better in data models with numeric data type keys rather than text keys associating the tables. It was plausible:
- It’s true in other places: in databases and even other BI platforms, a consistent data modeling best practice is to use integer (numeric) data types for keys.
- In Qlik (and databases and other BI platforms), numeric comparisons evaluate more quickly than text comparisons in conditions, e.g., flag = 1 is faster than flag = ‘yes’. One might infer that this also applies to comparing key field values between tables.
- Changing text keys to numeric using AutoNumber does improve calculation performance. I have seen it myself in careful tests, especially data models with link tables.
The truth is that key field data type does not matter, but the key field values do. Because the values matter, there may be a simple action you can take to improve performance in your Qlik apps — even if your key values are already numbers.
Why the key field data type doesn’t matter
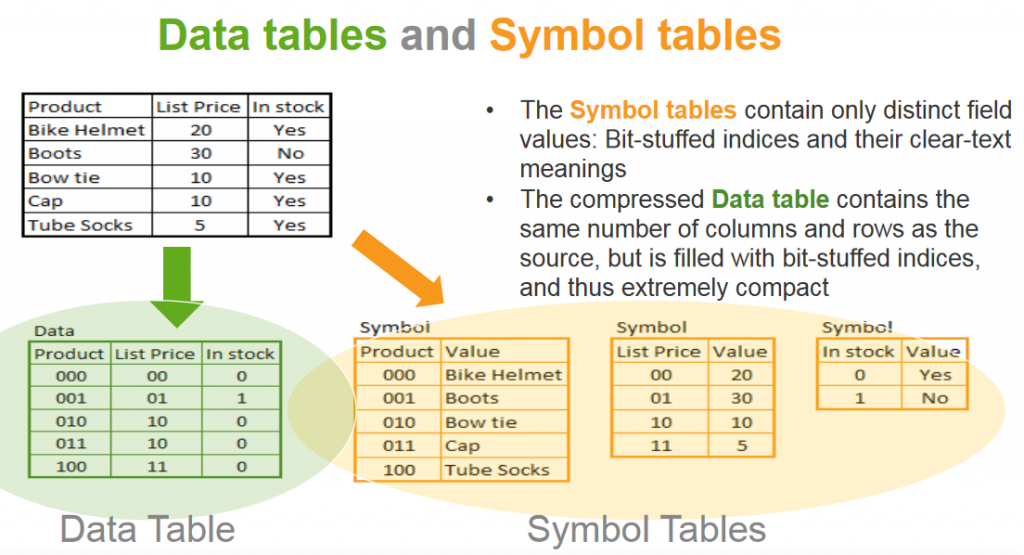
One way Qlik compresses data is storing each field’s unique values just once, in a symbol table, alongside a bit-stuffed pointer — a compact, unique identifier for each field value. (See image below, to better visualize.) Each unique field name has one symbol table, even if a field name is found in multiple tables.
Data tables mirror the structure of the data model as we see it, but they store only pointers — none of the field values themselves. These data tables get the human-understandable values from the symbol tables only when the Qlik UI needs it. For key fields, all data tables with the key field have pointers corresponding to the same set of symbol table values.
When a user selection or chart output requires the data model to use its associations, Qlik does this work using the key field pointers only. The pointers are adequate to figure out which rows are related without having to consider the human-understandable field values from the symbol table.
So, if the human-understandable values aren’t considered when processing associations, then obviously the data types of those values do not matter, either.
(My favorite resource on this topic is this QIX Engine presentation, by the OG, Henric Cronstrom. Internalizing the lessons from it help you understand a lot of behaviors in Qlik: why system functions are so fast, how list boxes are basically views into symbol tables, why field references aren’t qualified in the UI or many system functions, and more. I have seen it presented several times and am up to comprehending about 60% of it. 😂)
Why the key field values themselves do matter
Like me, you may have found that AutoNumbering your text keys improved performance, but if the field values aren’t considered for associations, why did it matter? In short: field values use data model storage, and smaller data models perform better.
Reducing the footprints of your applications improves calculation performance, even if you have more than enough RAM and the changes are not directly related to the interface design (like dropping fields you weren’t using anywhere).
AutoNumbering fields shrinks the data model footprint by dropping the human-understandable values from symbol table storage. After AutoNumbering a field, you can no longer see the original values, only sequential integers, based on the original load order of field values.
InternetService:
LOAD
InternetService,
AutoNumber(InternetService) as [InternetService (Autonumbered)]
FROM
[lib://Desktop/TelcoChurn.csv] (txt);

The most obvious candidate for AutoNumbering is concatenated text keys, which tend to have longgg text values that users don’t care about, but even fields that are already numeric — like IDs that are maintained by a database — can be made smaller with AutoNumber. And the best part is that it’s an improvement without tradeoffs from a user perspective, unlike trying to talk people into reducing the history carried in an application.
| Symbol table storage per field value | |
|---|---|
| Concatenated text key | Large |
| Natural numeric key, ex., IDs maintained by database | Small |
| Autonumbered key | None |
Side benefit: AutoNumbering a field automatically excludes it from search indexing and Smart Search, so reloads and global searches will be faster, too.
Find opportunities to AutoNumber (and measure the performance benefit): Qlik Sense Document Analyzer
The Qlik Sense Document Analyzer is a free utility from Rob Wunderlich (with contributions from Axis Group) that provides insights about your application, like how long charts take to calculate and what fields are unused. A field flag that recommends AutoNumbering key fields that are unused in the interface was added in version 1.8.
 |
 |
|---|
This also presents a natural opportunity to run the QSDA again, after the change, to note the difference in data model size and calculation performance.
The QSDA provides low-risk AutoNumber recommendations that are easy to detect and even generates the Load Script to implement the AutoNumbering, but there may be other candidates not flagged by it. Any field that is needed for your app to work but does not have values that are meaningful or useful to end users can be AutoNumbered. That may be a field that must have unique values retained to count but does not have values users will ever care to look at.
The simplest and best way to AutoNumber
The values that result from AutoNumbering are based on the load order of the fields in that reload instance. If you use QVD generators, trying to implement AutoNumbering and coordinating the values across applications is a complexity not worth the payoff. As a result, the best practice is to do the AutoNumbering in the user-facing application only, at the end of the script, where it can easily be applied to the entire resident data model.
The AutoNumber script command was introduced in June 2018. It runs instantaneously, accepts wildcard characters, and can be implemented in just one line of code, so it’s easy to comment out if you want to debug. We keep an example of the AutoNumber script command on the last tab of our UI template application, as a reminder.
//AUTONUMBER '$(HIDEPREFIX)Key*'; //AutoNumber all concatenated keys following naming convention //AUTONUMBER [Dim1], [Dim2]; //AutoNumber individual fields
Note from this example that consistent field naming makes your AutoNumbering code even simpler. If you apply a consistent naming convention for concatenated text keys, you can AutoNumber all of them with a single reference.
Before this script command was created, the AutoNumber script function had to be added to each load/field to AutoNumber, creating scattered code and slowing down reloads. If you have been skipping this simple optimization because it was such a pain to implement, or you still have it written using the function rather than the command, change it now!